
Discovery+
Automatically discover dark data, shadow data, unknown data, and sensitive data in a unified platform


Find, inventory, and classify all your data, everywhere: with agentless, AI augmented data discovery and advanced NLP customization: so that you can automatically find dark data, shadow data, and unknown date.
Uncover high risk data across on-prem and cloud, structured and unstructured, and accurately classify the data you know about - and the data you don't, wherever it lives.

Don't stop at cloud-native: get DSPM for IaaS, PaaS, SaaS, mainframes, dev tools, code repos, apps, big data & NoSQL, pipelines, on-prem, unstructured, semi-structured, and structured data.
Go beyond regular expressions and pattern matching, and find all data connected to a person across any data store; find crown jewel data; and leverage the latest ML for more accurate results, across your entire data estate.
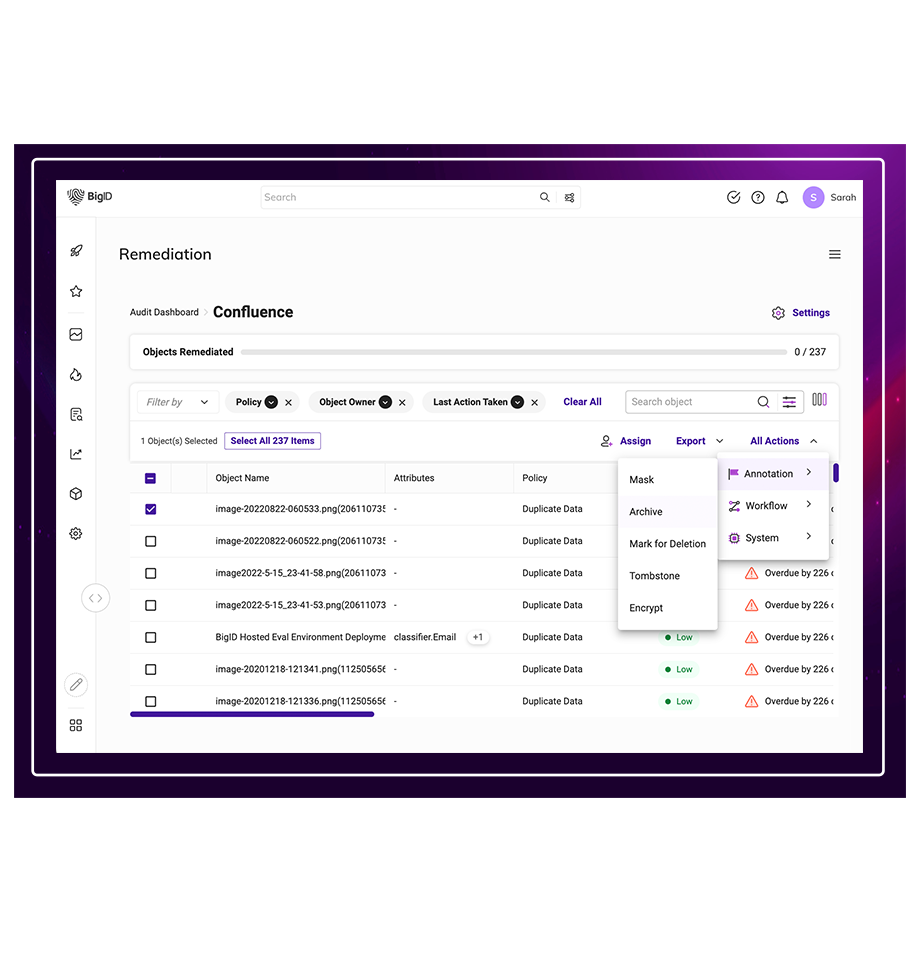
Remediate risk the way you want to: get centralized alerts based on risk, automatically trigger a Jira or ServiceNow ticket, delegate remediation to the right data owner, integrate with SOAR, revoke access, and even delete data directly.
Take action based on sensitivity, access, activity, toxicity, regulation, and policy. Elevate your data risk management with AI-driven context-based data remediation recommendations to make better, more informed decisions to reduce data risks.
Tools like BigID are the future.
Organizations should be leveraging these tools to remove the manual processes from data discovery, provide better visibility, and help with prioritization of controls.

Ryan O’Leary, Research Director – IDC The Future of Trust: Battling Data Discovery Confusion
BigID is a cloud friendly, AI powered platform
... that is particularly strong on discovering sensitive data of all types from across the enterprise.

Paul Fisher, Senior Analyst – KuppingerCole Market Compass for Data Governance Platforms
Very Powerful Tool .
With Excellent Value For Executing On Privacy And Security Goals. This product has a lot of usability and value.

Gartner Peer Insights Review
Automatically discover dark data, shadow data, unknown data, and sensitive data in a unified platform
Get customizable NLP classification that gives you accurate results for all data, everywhere

Identify overprivileged users and overexposed data, and easily assess who has access to what

Easily prioritize, manage, and alert on high-risk vulnerabilities and critical issues

Automatically report on risk with executive dashboards and reports, risk assessments, full audit capabilities, and more
Automate, guide, and orchestrate remediation for high-risk data, enforcing controls and eliminating noise

Implement Data Security Posture Management with enterprise security: including fully integrated RBAC and native security controls

Get more out of the box integrations with your tech stack: from SOAR to SIEM to CSPM and beyond

Deploy the way you want: on-prem, cloud, and hybrid based on your organization's environment.
Modern architecture design to scale with your data at petabyte scale - without affecting business or systems.
Advanced ML that nobody else has - from customizable NLP classifiers to graph tech for more depth & accuracy.
Deploy where you want: in the cloud, on prem, or across a hybrid environment - agentless & automated.

RBAC, Password Vault Support, Minimum Privileges, 2FA, Secure Cloud Deployment, No data duplication.
Choose the apps you need and build from there - with apps for privacy, security, and governance.

Integrate with your tech stack with partner apps or build your own on an open, API-first platform.
Get a custom demo with our data experts in privacy, protection, and perspective – and see BigID in action.






